
ワークフロー機能を2ヶ月でリリースした話

※本記事は2020年10月9日に作成されたblogを一部修正の上、再掲しています
こんにちは。
troccoでソフトウェアエンジニアを担当しております中根と申します。
本日は、私が開発リードを担当しましたワークフロー機能をリリースするまでの過程についてご紹介します。
経緯
ワークフロー/ジョブ管理といえば、Aiflow(CloudComposer), Digdagをはじめとして多くのOSSやサービスが存在しますが、デファクトとまで言えるようなものはまだないのが現状と思われます。
そのような中、troccoとしては、分析基盤構築に特化したシンプルなワークフロー機能を提供できればお客様により価値を感じていただけるのではないかと考え、開発の構想がスタートしました。
要件整理
2020年3月末より必要な機能を洗い出す作業を始めました。
初期利用頂ける予定のお客様がおりましたので、まずはそちらの要件を満たせることをMVP (実用最小限の製品: minimum viable product) としました。
MTGをしていたメンバー(CPO, CTO, 私)は普段からワークフロー/ジョブ管理ツールを利用していたエンジニアということもあり、その他にもあったらいいなという機能が沢山リストアップされましたが、
◎ MVPとし初期リリースするもの
○ 初期リリース後に順次対応していくもの (分析基盤構築に直結する利用用途、機能が明確、など)
△ 要望があり次第検討するが、現時点では開発ロードマップに含めないもの (機能が漠然としている、など)
とラベル付けしました。
◎機能のついでに実装できてしまいそうな○機能などもありましたが、初期リリースに含めるものはMVPである◎機能のみに徹底しました。
これにより、実装は元より動作確認などにかかる時間も必要最小限に削減できました。
UI
初期リリースのスコープが決定した後は、UI周りを詰める作業へと移りました。
ジョブの依存関係を次々に設定していくという機能の特性上、使いやすさがUIによって大きく左右されると考え、初期リリース時から熟慮を重ねたものを出したかったためです。
こちらは、CPO, デザイナー, 私というメンバーでテレカンをしながら、Figmaというツールを使いWeb上でリアルタイムに案を形にしていきました。
はじめは、ユーザーはジョブの依存関係だけを定義して、表示はシステム側に任せるという方針が濃厚でした。(例: CircleCI)
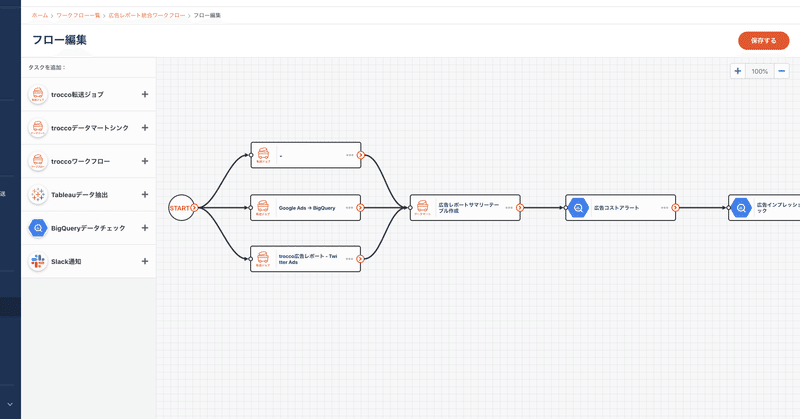
[初期の画面イメージ]
しかし、画面上で想定される操作(ジョブを追加する,ジョブを削除する,ジョブに依存関係を定義する,依存関係を削除する,各ジョブの詳細を設定する,など)を一つ一つどのようなインタラクションで行うのかと考えていくと、ドラッグ&ドロップしてジョブを追加していくような現在のスタイルが適しているのではないかという結論に至りました。
その後、すぐに実装には移らず、ペライチのモックページを仮実装して有志メンバー触ってもらうというフェーズを設けました。
静的な画像からはイメージしづらいインタラクションに関するフィードバックを得られ、実装後に触ってみたらなんか思ってたのと違う…といった手戻りを防ぐことができました。
また、フロントエンドの実装難度が高かったため、できることできないことを本格的に作り始める前に明確にしておくことができました。
例えば、当初はReact DnDというOSSを使っていましたが、拡大縮小をするためにはSVGである必要があり、このライブラリでは実現できなかったため、最終的にスクラッチでドラッグ&ドロップの処理を実装しました。
実装
UI側のフィードバックを待っている間に、実行基盤(スケジューリングなどのコアの部分)の実装にも着手しました。
必要最小限とはいえ、同時に並行して実行されるジョブ数の制限や、途中でキャンセルした場合の処理、など考慮する点は多く、細かい粒度で実装とテスト追加を繰り返していくこと進めていきました。
逐一テストを追加していくのが最初は時間がかかりましたが、コード量が増えていくとこれが功を奏したと考えています。
余談ですが、個人的に去年から趣味で競技プログラミングに取り組んでいて、ジョブのスケジューリングロジックやループの検知などにグラフアルゴリズムなどの知識を活かすことができました。
Webサービスの開発だとなかなか直接的に活かせることが少ないのでよかったと感じています。
ここでゴールデンウィークに突入します…
連休明け
この時点では、UIが大方Fix(上記のモック段階で本実装は未着手)、実行基盤のロジックが4,5割ほど実装済、といった状態でしたので、若干焦っておりました。
そのような中、ちょうどこのタイミングでジョインしてくれたメンバーや優秀なインターン生の力も借りることができ、今まで私一人で実装していましたが、三人体制で進めていけるようになりました。
その後は、それぞれ得意不得意な分野も微妙に違ったのでうまく分担して進めていくこともでき、無事に5月下旬にはステージング環境へのデプロイ、6月初旬にリリースを行うことができました。
リリース以降
無事に初期リリースを終えた以降は、
・BigQueryへのクエリ結果を元にエラー判定をする機能 (下記画像参考)
・フローの途中でSlack通知をする機能
・ワークフローから別ワークフローを呼び出す機能
・実行時間が長いワークフローをタイムアウトする機能
・実行中の同一ワークフローがある場合に、実行をスキップする機能
など、○に積んでいた機能を進めていきました。
(2020年10月現在では、○に積んでいた機能も9割リリースすることができました)
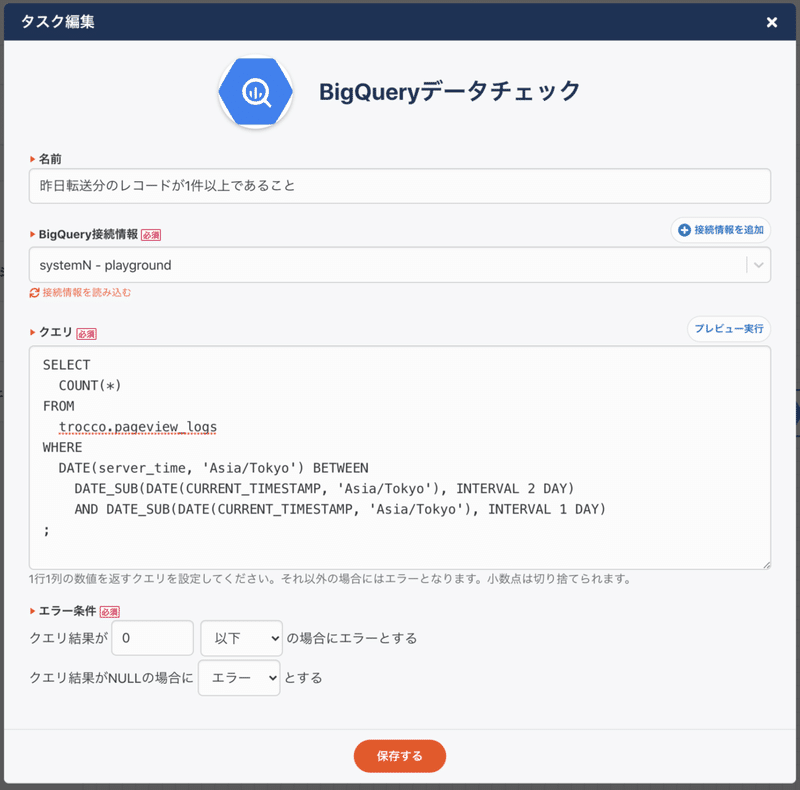
[BigQueryデータチェック機能]
あまり他のツールやサービスにはないような機能ですが、分析基盤構築に特化したというコンセプト機能に合致しているのではないかと思っています。
1. troccoの転送機能で様々なデータソースからBigQueryへ転送
↓
2. troccoのデータマート機能で1で転送したBigQuery内のデータをさらに集計
↓
3. BigQueryデータチェック機能で、(転送自体は成功したものの)異常な値となっていないかをチェック
↓
(エラーの場合はSlackなど各種通知先へ自動通知)
のようなワークフローをGUIから簡単に組むことができるようになりました。
まとめ
構想段階から2ヶ月ほどで初期リリースまで行うことができ、現在のところ目立った不具合もなく安定運用することができていると感じています。
良かった点としては
・実装を始める前に詰めるべき箇所は何度も議論を重ねた点。逆に手戻りのなさそうな箇所は並行して実装を進めていた点
・各タイミングで積極的にCPOにレビューに入ってもらった点。0ベースの新機能のため常に判断を求められましたが、軸がブレることなく進められました。
・でき得る限り細かい粒度で実装とテストを繰り返した点。複雑な基盤部分の安定性に寄与していると考えています。
などが挙げられると思っています。
悪かった点としては、私は夢にまでワークフローが出てきた点です笑
最後に
primeNumberでは共にサービスを作り上げてくれる仲間を積極的に募集しています。今回の記事を読んでご興味を持って頂けた方はぜひご連絡ください!